📅 스터디 날짜 | 2021.01.25
📖 모두의 데이터 분석 | Unit 09 p124-139
#1 barh의 두 매개변수 데이터 개수가 일치하지 않아, ValueError 발생
(1) 오류 분석

ValueError (값에 오류가 있음)
: x축의 데이터 개수와 찾은 데이터 개수가 일치하지 않아 발생한 에러
'제주'를 입력할 경우,
제주가 들어간 열이 많아서 데이터의 개수가 맞지 않기 때문에 오류가 발생한다.
plt.barh(range(101),m) : x축데이터 101개이지만, m에 저장된 데이터는 101개를 훨씬 넘는다.
len(m) = 4646, len(f) = 4646
import csv
f = open ('gender.csv')
data = csv.reader(f)
m=[]
f=[]
name = input('인구 구조가 알고 싶은 지역을 입력해 주세요 : ')
for row in data :
if name in row[0] :
for i in row[3:104] :
m.append(-int(i))
#m.append(-int(i).replace(',',''))
for i in row[106:] :
f.append(int(i))
import matplotlib.pyplot as plt
plt.rc('font',family='Malgun Gothic')
plt.title(name + '지역의 남녀 성별 인구 분포')
plt.rcParams['axes.unicode_minus']=False
plt.barh(range(101),m, label = '남성')
plt.barh(range(101),f, label = '여성')
plt.legend()
plt.show()
(2) 오류 해결
검색한 단어(name)가 들어간 열 중 첫 번째 열의 데이터를 저장한 후, 반복문을 종료(break)하여 해결한다.
즉, 아무리 그 단어가 포함된 열이 많다고 하더라도, len(m)과 len(f)는 101이 된다.
break : 반복문의 실행을 멈추는 키워드 (들여쓰기에 주의)
import csv
f = open ('gender.csv')
data = csv.reader(f)
m=[]
f=[]
name = input('인구 구조가 알고 싶은 지역을 입력해 주세요 : ')
for row in data :
if name in row[0] :
for i in row[3:104] :
m.append(-int(i))
for i in row[106:] :
f.append(int(i))
break #사용자로부터 입력받은 내용이 포함되는 데이터 중 처음 만나는 데이터만 m,f 데이터에 추가
import matplotlib.pyplot as plt
plt.rc('font',family='Malgun Gothic')
plt.title(name + '지역의 남녀 성별 인구 분포')
plt.rcParams['axes.unicode_minus']=False
plt.barh(range(101),m, label = '남성')
plt.barh(range(101),f, label = '여성')
plt.legend()
plt.show()
#2 원그래프
- 원그래프 = 파이차트 (pie chart)
- pie() : 전체 데이터 중 특정 데이터의 비율을 보기 쉽게 표현하는 함수
- plt.acix('equal') : 파이차트를 동그란 원으로 표현
- labels 속성을 통해 파이 차트의 각 항목에 이름을 표현할 수 있다.
- autopct 속성을 통해 각 항목의 비율을 자동으로 계산해 표시할 수 있다.
- colors 속성을 통해 파이차트의 색을 설정할 수 있다.
- explode 속성을 통해 특정 항목에 돌출하는 효과를 줄 수 있다. 0은 돌출되지 않음
데이터 순서를 통해 설정한다. 예로, explode(0, 0, 0.1, 0)이면 리스트의 세번째 데이터만 돌출되어 표현된다. - startangle 속성을 통해 시작 각도를 설정할 수 있다. 기본 시작 지점은 3시방향이며, 반시계방향으로 돈다.
startangle=90 이면 기본시작지점(3시방향)에서 반시계방향으로 90도 이동한 지점이 시작지점이 된다.
import matplotlib.pyplot as plt
plt.rc('font', family='Malgun Gothic')
size = [2441,2312,1031,1233] # size 리스트 생성
label = ['A형','B형','AB형','O형'] # label 리스트 생성
color=['darkmagenta','deeppink','hotpink','pink'] # color 리스트 생성
plt.axis('equal') #동그란 원형으로 표현
#autopct - 비율 표시 (%.1f%% = 소수점 아래 첫 번째 소수점까지 표현)
#labels - 레이블 추가 /colors - 색상 설정 /explode - 돌출효과
plt.pie(size, labels=label, autopct='%.1f%%', colors=color, explode=(0,0,0.1,0))
plt.legend() # 범례 표시
plt.show()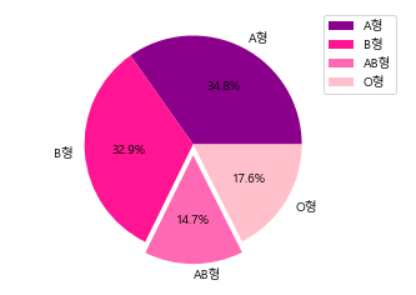
import csv
f = open('gender.csv')
data = csv.reader(f)
size = []
name = input('찾고 싶은 지역의 이름을 알려주세요 : ')
for row in data :
if name in row[0] :
m = 0
f = 0
for i in range(101) :
m += int(row[i+3])
f += int(row[i+106])
break
size.append(m)
size.append(f)
import matplotlib.pyplot as plt
plt.rc('font',family='Malgun Gothic')
color = ['crimson', 'darkcyan']
plt.axis('equal')
plt.pie(size,labels=['남','여'], autopct='%.1f%%', colors=color, startangle=90)
plt.title(name+' 지역의 남녀 성별 비율')
plt.show()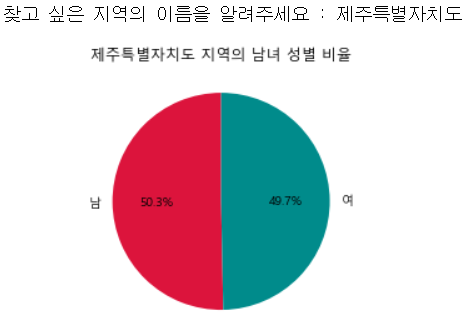
🤐
오류가 이래저래 많이 생겨서 머리 아팠던 유닛이었다.
'💻프로그래밍 > 🕵️♀️모두의데이터분석' 카테고리의 다른 글
| [파이썬] 08. 막대그래프/수평막대그래프/항아리모양그래프 (0) | 2021.01.26 |
|---|---|
| [파이썬] 07. 행안부데이터다운/ggplot스타일/인구구조시각화 (0) | 2021.01.26 |
| [파이썬] 06. 히스토그램/상자그림/랜덤값 (0) | 2021.01.26 |
| [파이썬] 05. len()/split()/꺾은선그래프/조건 데이터 출력 (1) | 2021.01.25 |
| [파이썬] 04. matplotlib라이브러리/선그래프/그래프옵션(제목,범례,색상,선모양,마커모양) (0) | 2021.01.24 |